Re: Zadaci za wannabe pythoniste
Re: Zadaci za wannabe pythonisteCitat:
B3R1:
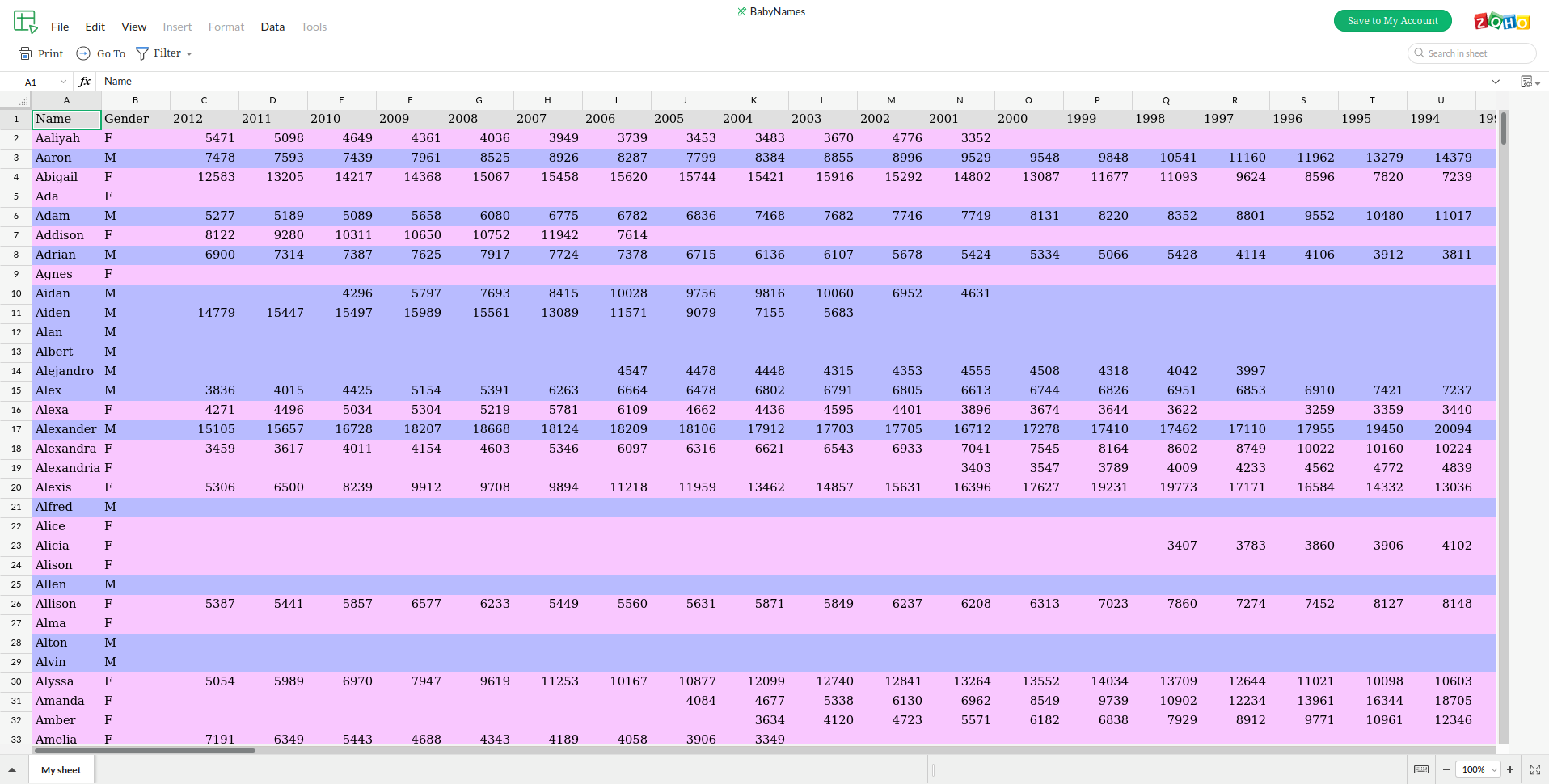
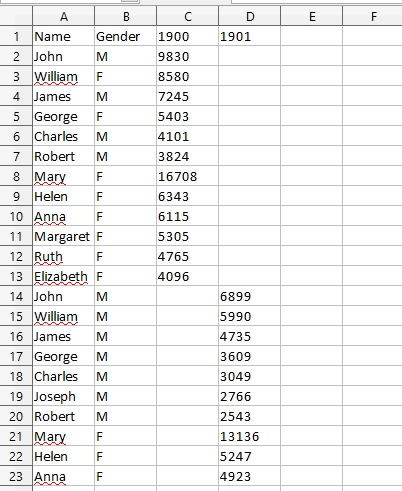
Napravio si dve greske. Prva je klasican problem "kumulativnog trpanja" podataka u niz. Problem je sto promenljive lista_m, lista_z i lista_unikat praznis samo na pocetku. Svaki sledeci fajl koji otvoris ih "nasledjuje" u potpunosti i kumulativno dodaje imena u njih. Otuda ti se npr. Shannon, koji se javlja prvi put 1972. godine provlaci i dalje kroz sve naredne godine. Problem zapravo pocinje jos od 1954, gde je Leslie nasledjen(a) iz 1953. i nadalje se provlaci kroz naredne godine. Ok, ovo nije tesko resiti, inicijalizaciju treba ukloniti s vrha i staviti iza linije
Recimo nesto ovako (nisam testirao, moguce je da sam napravio neki bag, ali ideja je tu):
Citat:
a1234567:
"mali" problem da se javljaju neka imena kojih nema u oba spiska za datu godinu (na primer Shannon), al nemam pojma zašto:
"mali" problem da se javljaju neka imena kojih nema u oba spiska za datu godinu (na primer Shannon), al nemam pojma zašto:
Napravio si dve greske. Prva je klasican problem "kumulativnog trpanja" podataka u niz. Problem je sto promenljive lista_m, lista_z i lista_unikat praznis samo na pocetku. Svaki sledeci fajl koji otvoris ih "nasledjuje" u potpunosti i kumulativno dodaje imena u njih. Otuda ti se npr. Shannon, koji se javlja prvi put 1972. godine provlaci i dalje kroz sve naredne godine. Problem zapravo pocinje jos od 1954, gde je Leslie nasledjen(a) iz 1953. i nadalje se provlaci kroz naredne godine. Ok, ovo nije tesko resiti, inicijalizaciju treba ukloniti s vrha i staviti iza linije
lines = open(filename).readlines()Medjutim, tu postoji jos jedan problem: glob.glob() i os.listdir() vracaju listu fajlova sortiranu po nekoj internoj logici operativnog sistema. Dok Windows sortira fajlove po imenima, Unix/Linux vraca totalno nesortirane fajlove. Znaci, trebalo bi dodati:
for filename in sorted(glob.glob('*txt')):Na kraju, lepo je sto si iskoristio skup kao strukturu podataka, jer ti to efikasno resava 'uniq' funkciju. Ali sta ce ti onda liste koje pretvaras u skup? Zasto odmah ne koristis skup.add() za dodavanje elementa u skup? Inace, add() funkcija lepo ignorise elemente koji vec postoje u skupu, odnosno dodaje element samo ako vec nije u skupu. Takodje, s obzirom da svaka godina ima muska i zenska imena, nebitno je ispitivati da li je 'Boys' ili 'Girls' u imenu fajla i beleziti posebno muska i zenska imena.Recimo nesto ovako (nisam testirao, moguce je da sam napravio neki bag, ali ideja je tu):
Code (python):
import glob
spisak = open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/unisex.txt', 'w')
imena = {}
for filename in sorted(glob.glob('*txt')):
godina = int(filename[0:4])
lines = open(filename).readlines()
lista= set() # Lista imena u fajlu, pol je nebitan
for line in lines:
name = line.strip().split()[0]
lista.add(name)
if (godina not in imena): # U prvom fajlu iz godine X hashtable imena je prazna
imena[godina] = lista
else: # U drugom fajlu iz godine X trazimo uniq(m,f)
imena[godina] = imena[godina].intersection(lista)
spisak.write(str(imena) + '\n')
spisak.close()
import glob
spisak = open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/unisex.txt', 'w')
imena = {}
for filename in sorted(glob.glob('*txt')):
godina = int(filename[0:4])
lines = open(filename).readlines()
lista= set() # Lista imena u fajlu, pol je nebitan
for line in lines:
name = line.strip().split()[0]
lista.add(name)
if (godina not in imena): # U prvom fajlu iz godine X hashtable imena je prazna
imena[godina] = lista
else: # U drugom fajlu iz godine X trazimo uniq(m,f)
imena[godina] = imena[godina].intersection(lista)
spisak.write(str(imena) + '\n')
spisak.close()
Da, kad prebacim liste u petlju, radi.
Meni je bila ideja da pokupim sva muška imena u jednu listu, sva ženska u drugu i onda nađem presek te dve liste.
Kod tvog koda mi nisu baš najjasnije neke stvari. Evo kako ga ja čitam:
Code:
for filename in sorted(glob.glob('*txt')): # OK, sortiranje fajlova pre otvaranja, da bi išlo po godinama, mada kod men u WIn to je već sortirano.
godina = int(filename[0:4]) # beleži prva 4 karaktera iz imena fajla, što je godina
lines = open(filename).readlines() # učitava u memoriju ceo tekst fajla
lista= set() # tip liste je skup, što znači nema ponavljanja
for line in lines:
name = line.strip().split()[0] # promenljiva name je indeks[0] u listi, npr. ['James', 32340]
lista.add(name) # dodaje to ime u listu
OVDE IMAM PROBLEM: kad dovde izvršim program za jednu godinu sa:
for filename in sorted(glob.glob('1990*txt')):)
u listi imam samo ženska imena:
{'Stephanie', 'Maria', 'Lindsay', 'Anna', 'Shannon', 'Julie', 'Hannah', 'Katie', 'Kelly', 'Lindsey', 'Kathleen', 'Ashley', 'Veronica',
'Mary', 'Angela', 'Elizabeth', 'Cassandra', 'Shelby', 'Tiffany', 'Jenna', 'Brooke', 'Andrea', 'Tara', 'Jessica', 'Katelyn', 'Kelsey',
'Amy', 'Erin', 'Alicia', 'Alexandra', 'Laura', 'Holly', 'Diana', 'Brianna', 'Gabrielle', 'Kathryn', 'Whitney', 'Sarah', 'Jennifer', 'Catherine',
'Kristin', 'Emily', 'Amanda', 'Megan', 'Christine', 'Victoria', 'Alyssa', 'Courtney', 'Alexis', 'Erika', 'Melissa', 'Michelle', 'Danielle',
'Sara', 'Kimberly', 'Katherine', 'Olivia', 'Ariel', 'Cynthia', 'Meghan', 'Rebecca', 'Samantha', 'Monica', 'Patricia', 'Leah', 'Christina',
'Taylor', 'Julia', 'Morgan', 'Nicole', 'Heather', 'Marissa', 'Brittany', 'Rachel', 'April', 'Kaitlyn', 'Erica', 'Natalie', 'Brittney', 'Vanessa',
'Caitlin', 'Abigail', 'Lisa', 'Jacqueline', 'Kristen', 'Chelsea', 'Kristina', 'Bianca', 'Molly', 'Alexandria', 'Paige', 'Jamie', 'Jordan', 'Kayla',
'Amber', 'Jasmine', 'Melanie', 'Lauren', 'Allison', 'Crystal'}
Šta se dešava sa muškim imenima? Koji je smisao ove liste?
I onda mi ni ovo što sledi nije jasno:
if (godina not in imena): # U prvom fajlu iz godine X hashtable imena je prazna
imena[godina] = lista
else: # U drugom fajlu iz godine X trazimo uniq(m,f)
imena[godina] = imena[godina].intersection(lista)
for filename in sorted(glob.glob('*txt')): # OK, sortiranje fajlova pre otvaranja, da bi išlo po godinama, mada kod men u WIn to je već sortirano.
godina = int(filename[0:4]) # beleži prva 4 karaktera iz imena fajla, što je godina
lines = open(filename).readlines() # učitava u memoriju ceo tekst fajla
lista= set() # tip liste je skup, što znači nema ponavljanja
for line in lines:
name = line.strip().split()[0] # promenljiva name je indeks[0] u listi, npr. ['James', 32340]
lista.add(name) # dodaje to ime u listu
OVDE IMAM PROBLEM: kad dovde izvršim program za jednu godinu sa:
for filename in sorted(glob.glob('1990*txt')):)
u listi imam samo ženska imena:
{'Stephanie', 'Maria', 'Lindsay', 'Anna', 'Shannon', 'Julie', 'Hannah', 'Katie', 'Kelly', 'Lindsey', 'Kathleen', 'Ashley', 'Veronica',
'Mary', 'Angela', 'Elizabeth', 'Cassandra', 'Shelby', 'Tiffany', 'Jenna', 'Brooke', 'Andrea', 'Tara', 'Jessica', 'Katelyn', 'Kelsey',
'Amy', 'Erin', 'Alicia', 'Alexandra', 'Laura', 'Holly', 'Diana', 'Brianna', 'Gabrielle', 'Kathryn', 'Whitney', 'Sarah', 'Jennifer', 'Catherine',
'Kristin', 'Emily', 'Amanda', 'Megan', 'Christine', 'Victoria', 'Alyssa', 'Courtney', 'Alexis', 'Erika', 'Melissa', 'Michelle', 'Danielle',
'Sara', 'Kimberly', 'Katherine', 'Olivia', 'Ariel', 'Cynthia', 'Meghan', 'Rebecca', 'Samantha', 'Monica', 'Patricia', 'Leah', 'Christina',
'Taylor', 'Julia', 'Morgan', 'Nicole', 'Heather', 'Marissa', 'Brittany', 'Rachel', 'April', 'Kaitlyn', 'Erica', 'Natalie', 'Brittney', 'Vanessa',
'Caitlin', 'Abigail', 'Lisa', 'Jacqueline', 'Kristen', 'Chelsea', 'Kristina', 'Bianca', 'Molly', 'Alexandria', 'Paige', 'Jamie', 'Jordan', 'Kayla',
'Amber', 'Jasmine', 'Melanie', 'Lauren', 'Allison', 'Crystal'}
Šta se dešava sa muškim imenima? Koji je smisao ove liste?
I onda mi ni ovo što sledi nije jasno:
if (godina not in imena): # U prvom fajlu iz godine X hashtable imena je prazna
imena[godina] = lista
else: # U drugom fajlu iz godine X trazimo uniq(m,f)
imena[godina] = imena[godina].intersection(lista)