



 Optimizacija pretrage dupliranih fajova
Optimizacija pretrage dupliranih fajovaDakle treba naci sve fajlove na hardu, ubaciti info o njima u memoriju i uporediti svaki sa svakim. To sam uradio preko resizable arraya, znaci prvo alociram memoriju recimo 10kb i nju popunjavam sa informacijama svakog fajla koga nadjem.
Kad se ona popuni onda zovem funkciju koja prosiruje taj memorijski blok na jos 10kb
i sve tako dok ima fajlova. Na kraju dobijem array sa informacijama o fajlovima,
te informacije stavljam u moju strukturu koja sadrzi ime fajla, path, velicinu, atribute..
E sad dolazi uporedjivanje, za n fajlova ima n(n-1)/2 poredjenja, uzimam prvu strukturu
u nizu i poredim je sa svakom sledecom, znaci pocinjem poredjenje od druge pa do kraja niza.
Kad zavrsim sa prvom uzimam drugu i poredim je sa trecom i svakom sledecom do kraja niza itd..
Sve je to lepo ali provalio sam da je sporo, meni treba 10minuta da izvrsi sva poredjenja
dok Windows commanderu za isti posao treba 2 minuta!!!
Struktura izgleda otprilike ovako (MASM32 sintaksa):
Code:
FileInfo struct
szFileName db MAX_PATH dup(?) ; name of file
CreationTime FILETIME <?> ; file's time of creation
ModifyTime FILETIME <?> ; file's last write time
dwSize dd ? ; file size
dwAttributes dd ? ; file attributes
FileInfo ends
FileInfo struct
szFileName db MAX_PATH dup(?) ; name of file
CreationTime FILETIME <?> ; file's time of creation
ModifyTime FILETIME <?> ; file's last write time
dwSize dd ? ; file size
dwAttributes dd ? ; file attributes
FileInfo ends
Znaci postoji niz ovakvih struktura, info o fajlovima ne ubacujem po nekom redosledu vec kako koji
fajl nadjem (FindFirstFile/FindNextFile) tako ga ubacim.
Pri poredjenju prvo poredim ove dword-ove, pa ako su isti onda stringove (filename)
jer za to treba manje vremena nego da poredim prvo stringove.
E sad, ja vise nemam ideja kako da ovo optimizujem dalje. I kad bi uspeo nesto sigurno ne bi
dobio toliko poboljsanje na nivou windows commandera.
-I know UNIX, PASCAL, C, FORTRAN,
COBOL, and nineteen other high-tech
words.
COBOL, and nineteen other high-tech
words.
 Re: Optimizacija pretrage dupliranih fajova
Re: Optimizacija pretrage dupliranih fajova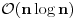
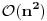
 Re: Optimizacija pretrage dupliranih fajova
Re: Optimizacija pretrage dupliranih fajova
